Stable Diffusion에 대한 이미지에서 프롬프트를 얻는 방법

정말 마음에 드는 AI 이미지를 보고 프롬프트가 무엇인지 궁금해하신 적이 있나요? 이미지에서 프롬프트를 얻는 몇 가지 방법을 살펴보겠습니다. 또한 이미지를 다시 만들 가능성을 높이는 추가 기술도 배우게 됩니다.
이 기사에서는 다음 방법을 배웁니다.
- 때때로 프롬프트가 작성되는 PNG 메타데이터 정보를 읽습니다.
- CLIP 질문기를 사용하여 프롬프트를 추측하세요.
- 이미지 재현을 위한 팁.
소프트웨어 설정
이 튜토리얼에서는 AUTOMATIC1111 Stable Diffusion WebUI를 사용합니다. 인기가 있고 무료입니다. 이 소프트웨어는 Windows , Mac 또는 Google Colab 에서 사용할 수 있습니다.
Stable Diffusion을 처음 사용하는 경우 빠른 시작 가이드를 확인하세요. AUTOMATIC1111 을 처음 사용하는 경우 AUTOMATIC1111 가이드를 확인하세요.
방법 1: PNG 정보를 읽어 이미지에서 프롬프트 가져오기
AI 이미지가 PNG 형식인 경우 프롬프트 및 기타 설정 정보가 PNG 메타데이터 필드에 기록되었는지 확인할 수 있습니다.
먼저 이미지를 로컬 저장소에 저장합니다.
AUTOMATIC1111 WebUI를 엽니다. PNG 정보 페이지 로 이동합니다 .
이미지를 왼쪽의 소스 캔버스 에 끌어다 놓습니다 .
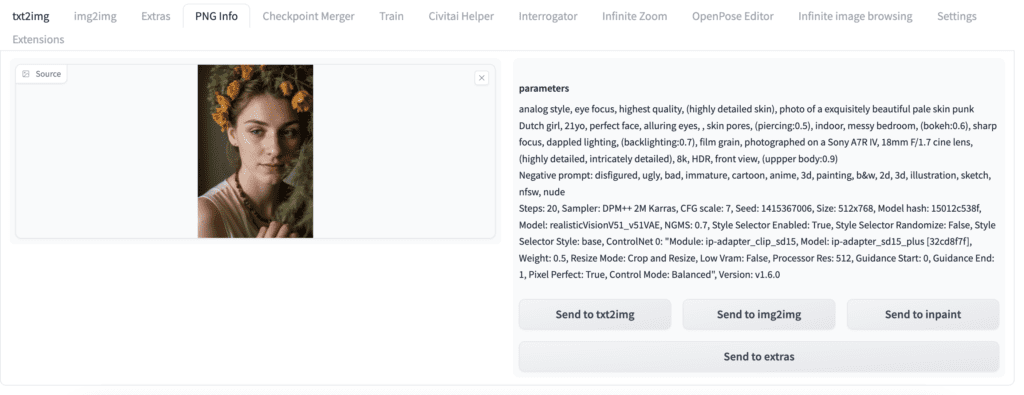
이미지 파일에 있는 경우 프롬프트, 부정 프롬프트 및 기타 생성 매개변수가 오른쪽에 표시됩니다. 선택적으로 프롬프트와 설정을 txt2img, img2img , inpainting 또는 업스케일링을 위한 Extras 페이지로 보낼 수 있습니다 .
또는 이 무료 사이트를 사용하여 AUTOMATIC1111을 사용하지 않고 PNG 메타데이터를 볼 수 있습니다.
방법 2: CLIP 인터로게이터를 사용하여 이미지에서 프롬프트를 추측합니다.
첫 번째 방법이 작동하지 않는 경우가 많습니다. 애초에 세대 정보가 기록되지 않았을 수도 있습니다. 거기에 있었을 수도 있지만 웹 서버가 이미지 최적화 중에 이를 제거했습니다. 또는 Stable Diffusion에 의해 생성되지 않았습니다.
이 경우 다음 옵션은 CLIP 인터로게이터를 사용하는 것입니다 . 이미지의 캡션을 추측하는 AI 모델 클래스입니다. AI 이미지뿐만 아니라 모든 이미지에서 작동합니다.
CLIP이란 무엇인가요?
CLIP(Contrastive Language-Image Pre-training)은 시각적 개념을 자연어에 매핑하는 신경망입니다. CLIP 모델은 엄청난 수의 이미지와 캡션 쌍으로 학습됩니다.
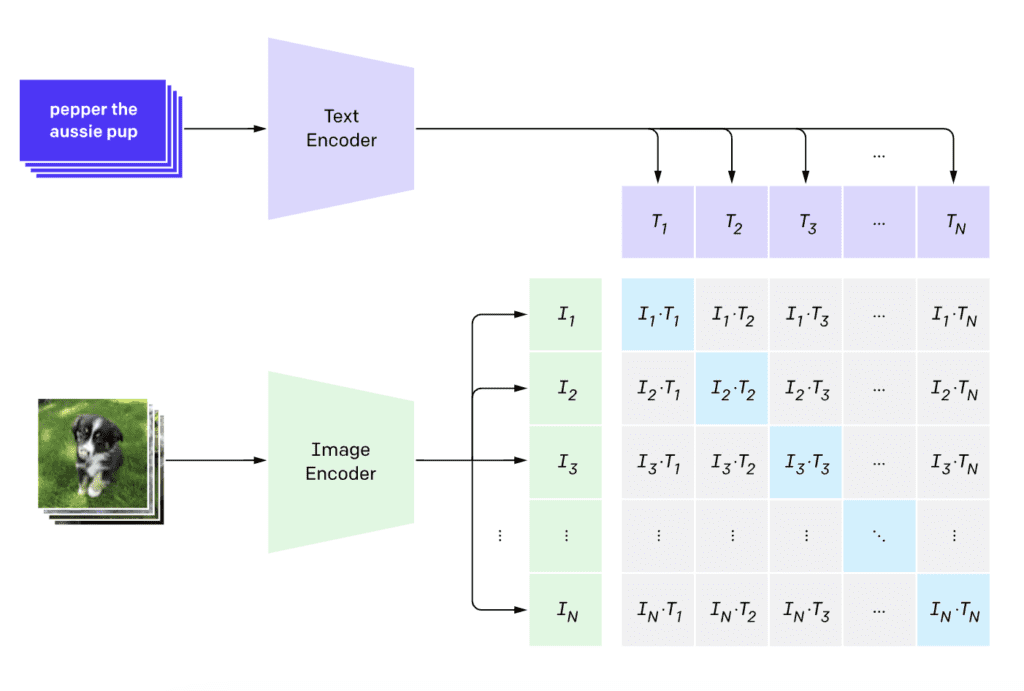
대조 언어-이미지 사전 훈련(CLIP)(이미지 출처: OpenAI.)
이미지가 주어지면 CLIP 모델은 이미지를 설명하는 캡션을 추론할 수 있습니다. 사용 사례에서는 캡션을 프롬프트로 사용합니다.
WebUI의 기본 CLIP 질문자
확장 기능을 설치하지 않으려면 img2img 페이지에서 AUTOMATIC1111의 기본 CLIP 인터로게이터를 사용할 수 있습니다. 이는 Junnan Li와 동료들이 쓴 " BLIP: 통합 비전-언어 이해 및 생성을 위한 부트스트래핑 언어-이미지 사전 훈련 " 기사에 설명된 CLIP 모델인 BLIP 을 사용합니다.
기본 CLIP 질문기를 사용하려면:
- AUTOMATIC11111을 엽니다.
2. img2img 페이지로 이동합니다.
3. img2img 캔버스 에 이미지를 업로드합니다 .
4. 질문을 받으려면 CLIP 질문을 클릭하세요.
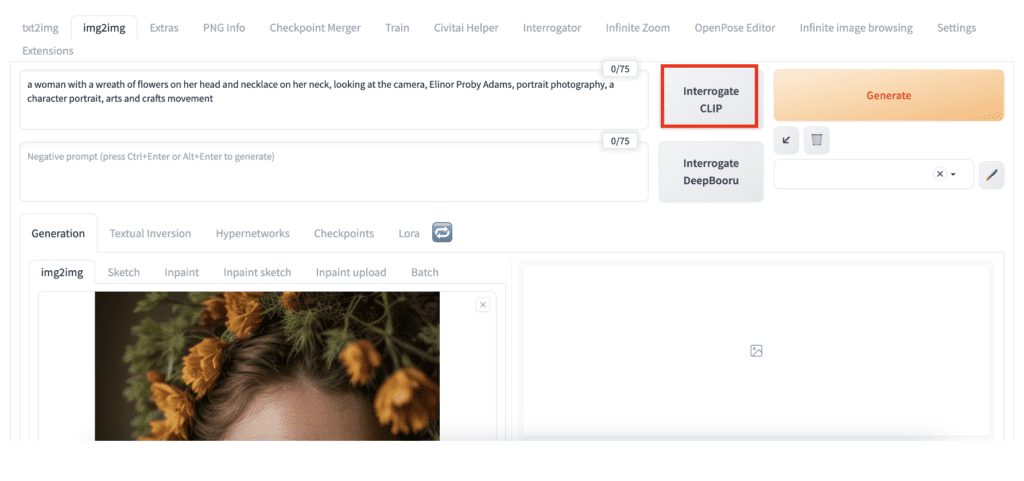
머리에 꽃 화환을 쓰고 목에 목걸이를 걸고 카메라를 바라보는 여성, 엘리너 프로비 아담스, 인물 사진, 캐릭터 초상화, 예술 및 공예 운동
현실적인 비전 모델 과 현실적인 사람들에 대한 부정적인 프롬프트를 사용하여 이 프롬프트를 테스트하면 다음 이미지를 얻을 수 있습니다.

구성은 다르지만 목걸이와 화환을 착용한 여성이 등장합니다.
CLIP 질문기 확장
AUTOMATIC1111의 기본 CLIP 질문기는 다른 CLIP 모델을 사용하는 것을 허용하지 않습니다. 추가 기능을 원하면 CLIP 질문기 확장을 사용해야 합니다 .
권장 확장 프로그램 페이지 의 지침에 따라 설치하세요. 확장 프로그램의 URL은 다음과 같습니다.
https://github.com/pharmapsychotic/clip-interrogator-extCLIP 인터로게이터 확장을 사용하려면
- AUTOMATIC1111 WebUI를 엽니다.
2. 질문자 페이지로 이동합니다.
3. 이미지를 이미지 캔버스에 업로드합니다.
4. CLIP 모델 드롭다운 메뉴 에서 ViT-L-14-336/openai를 선택합니다 . Stable Diffusion v1.5에서 사용되는 언어 임베딩 모델 입니다 .
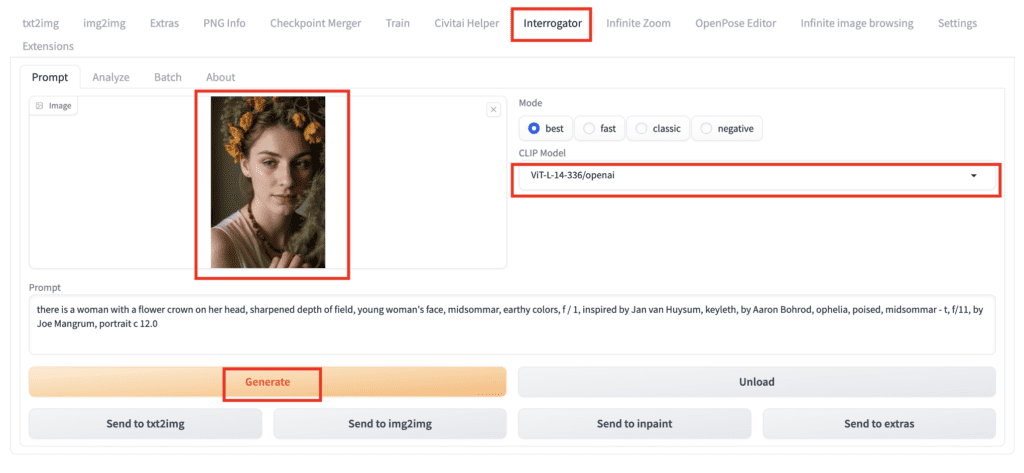
5. 생성을 클릭하여 프롬프트를 생성합니다.
이것이 우리가 얻은 것입니다.
머리에 꽃관을 쓴 여성이 있습니다. 피사계 심도, 흙빛 톤, 메리골드, 귀여운 여성의 초상화, 드라이어드, 프레임 중앙에 있는 피사체, 젊은 여성, 미드소마, 얼굴 초상화, 65mm 1.5x 아나모픽 렌즈 , Elsa Beskow에서 영감을 받음, 예술 :: 전문 사진, 드루이드 초상화
이전 섹션과 동일한 이미지 설정을 사용하여 다음 이미지를 얻습니다.

다시 말하지만, 비슷하지만 완전히 동일하지는 않습니다. 메시지에는 그녀의 목걸이가 없어 이미지에도 표시되지 않습니다. CLIP 질문기의 결과는 상당히 다양하므로 ViT-L-14-336/openai 모델이 BLIP보다 나쁘다고는 말하지 않겠습니다.
SDXL 모델에 대한 CLIP 조사
프롬프트가 SDXL( Stable Diffusion XL ) 모델과 함께 사용되도록 의도된 경우 Interrogate 페이지의 CLIP 모델 드롭다운 메뉴 에서 ViT-g-14/laion2b_s34b_b88k를 선택할 수 있습니다 .
그러면 다음과 같은 프롬프트가 표시됩니다.
머리에 꽃관을 쓴 여성, 중간 인물 상단 조명, f/1, 추가 – 세부 사항, 1 8 yo, 내셔널 지오그래픽 사진 촬영, 영화 장면 인물 근접 촬영, William Morris에서 영감을 받음, 중앙 프레임 인물 사진, lut, 따뜻한 빛, 생체 영감, 집에서, f / 2 0, Jane Kelly
SDXL 1.0 기본 + 구체화 모델로 생성된 이미지입니다.

프롬프트와 모델은 원본 구성에 더 가까운 이미지를 생성했습니다.
Stable Diffusion으로 AI 이미지를 재현하는 팁
이미지에서 프롬프트를 얻으려면 항상 PNG 정보 방법(방법 1)을 먼저 시도해야 합니다 . 운이 좋으면 이미지를 재생성하는 데 필요한 전체 정보를 얻을 수 있기 때문입니다. 여기에는 프롬프트 , 모델 , 샘플링 방법 , 샘플링 단계 등이 포함됩니다.
Stable Diffusion v1.5 및 XL 모델에 대해 BLIP 및 CLIP 모델을 실험해 볼 수 있습니다. ViT-g-14/laion2b_s34b_b88k는 SDXL뿐만 아니라 v1.5 모델에서도 꽤 잘 작동할 수 있습니다.
주저하지 말고 프롬프트를 수정하세요. 위의 예에서 볼 수 있듯이 프롬프트가 올바르지 않거나 일부 개체가 누락될 수 있습니다. 이미지를 올바르게 설명하도록 프롬프트를 적절하게 편집하세요.
적절한 체크포인트 모델을 선택하는 것이 중요합니다. 프롬프트에 반드시 올바른 스타일이 포함될 필요는 없습니다. 예를 들어 현실적인 사람을 생성하려면 현실적인 모델을 선택하십시오.
마지막으로 핵 옵션은 이미지 프롬프트를 사용하는 것입니다. 하지만 다음 포스팅을 위해 남겨두겠습니다!