인상적인 새로운 AI 모델 - Mixtral 8x7B - Mistral AI가 제작한 GPT-4의 컴팩트 버전
이번주에는 정말 좋은 작품이 많이 나왔습니다.
프랑스 스타트업 미스트랄(Mistral)은 많은 사람들이 주목하고 있는 전문가 혼합, 개방형 가중치 모델을 출시했습니다.
Microsoft는 일부 벤치마크에서 Llama-2 70B보다 성능이 뛰어난 인상적인 작은 언어 모델(2.7B 매개변수)을 출시했습니다. Google은 Med-PaLM 2의 후속 제품으로 MedLM과 텍스트-이미지 모델인 Imagen의 새 버전을 출시했습니다.

지난 주, 프랑스 스타트업인 Mistral AI는 모금 4억 1,500만 달러를 모금했을 뿐만 아니라 감소했습니다.
전문가 모델인 Mixtral-8x7B의 멋지고 새로운 희소 혼합 모델이 새로운 플랫폼 서비스의 베타 출시를 발표했습니다.
Mixtral-8x7B는 대부분의 벤치마크에서 Llama 2 70B 모델보다 성능이 뛰어나며 6배 더 빠른 추론을 제공합니다.
또한 Apache 2.0 라이센스와 함께 출시된 개방형 모델이므로 누구나 자신의 프로젝트에 액세스하고 사용할 수 있습니다.
Mistral AI의 최신 창작물인 Mixtral 8x7B는 GPT-4에 대한 작지만 강력한 대안으로 등장합니다.
AI 환경에서 주목할만한 사건이 방금 일어났습니다. Mistral AI의 Mixtral 8x7B는 상당한 발전이 돋보입니다.
이 오픈 소스 LLM(대형 언어 모델)은 단순한 새로운 추가 기능 그 이상입니다. 로컬 미니 GPT-4와 비슷합니다.
Mixtral 8x7B: GPT-4의 컴팩트 버전
Mixtral 8x7B는 GPT-4의 작고 효율적인 버전으로 보다 관리하기 쉽고 접근하기 쉬운 형태로 고급 AI 기능을 제공합니다.
유사한 전문가 혼합(MoE) 채택 Mistral AI는 축소된 형식으로 다양한 애플리케이션을 위한 실용적인 대안이 됩니다.
Mixtral 8x7B의 주요 측면:
- 구조: GPT-4의 대규모 규모에 비해 각각 70억 개의 매개변수를 가진 8명의 전문가를 활용합니다.
- 효율적인 처리: 추론을 위해 토큰당 전문가 2명만 고용하여 GPT-4의 효율성을 반영합니다.
기술적 매개변수:
- 크기: 모델은 8x Mistral 7B보다 작은 87GB로 크기 감소를 위한 공유 주의 매개변수를 나타냅니다.
- GPT-4와의 비교: 전문가 수는 2배, 전문가당 매개변수는 24배 감소하여 총 420억 개의 매개변수로 추정됩니다.
컨텍스트 용량:
- GPT-4와 유사한 32K 컨텍스트 크기를 유지하여 강력한 성능을 보장합니다.

모두가 Mistral AI의 새로운 LLM Drop에 대해 이야기하는 이유는 무엇입니까?
- Mistral AI에서 개발: 파리에 본사를 둔 이 스타트업은 기술 전문성과 오픈소스 접근성을 결합하여 주목을 받았습니다.
- AI 산업에 미치는 영향: Mixtral 8x7B의 출시는 패러다임 전환을 알리고 업계 규범에 도전하며 AI 기술의 민주화를 촉진합니다.
- AI 성과 추가 그 이상: Mixtral 8x7B는 AI 혁신 목록을 강화하는 것 이상입니다. 이는 기존 표준에 도전하고 혁신과 탐구를 위한 새로운 길을 열어줍니다.
- 개방적이고 접근 가능한 AI를 위한 길 닦기: Mixtral 8x7B를 사용한 Mistral AI의 접근 방식은 AI 개발의 개방성과 협업에 대한 새로운 선례를 설정합니다.
Mixtral 8x7B 토렌트 다운로드
평소의 정교한 출시 대신 Mistral AI는 Mixtral 8x7B의 고유한 경로를 선택하여 토렌트 링크를 통해 출시했습니다.
최신 Mixtral 87XB 모델을 다운로드할 수 있는 토렌트 링크는 다음과 같습니다.
magnet:?xt=urn:btih:208b101a0f51514ecf285885a8b0f6fb1a1e4d7d&dn=mistral-7B-v0.1&tr=udp%3A%2F%http://2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=https%3A%2F%https://t.co/HAadNvH1t0%3A443%2Fannounce
RELEASE ab979f50d7d406ab8d0b07d09806c72c
magnet:?xt=urn:btih:5546272da9065eddeb6fcd7ffddeef5b75be79a7&dn=mixtral-8x7b-32kseqlen&tr=udp%3A%2F%http://2Fopentracker.i2p.rocks%3A6969%2Fannounce&tr=http%3A%2F%http://2Ftracker.openbittorrent.com%3A80%2Fannounce
RELEASE a6bbd9affe0c2725c1b7410d66833e24
이 접근 방식은 Google 및 OpenAI와 같은 회사의 보다 조직화된 릴리스와 완전히 대조되며, 스펙터클을 만드는 것보다 성명을 발표하는 데 더 중점을 둡니다.
색다른 릴리스는 모델의 기능을 강조했을 뿐만 아니라 AI 기술의 미래와 오픈 소스 모델의 역할에 대한 대화를 촉발시켰습니다.
Mixtral 8x7B는 어떻게 작동하나요?
Mixtral 8x7B의 중심부로 들어가면 Mistral AI의 전문성과 비전에 대한 증거인 현대 AI 엔지니어링의 경이로움을 발견할 수 있습니다. 이 모델은 널리 호평을 받고 있는 GPT-4의 작은 형제 그 이상입니다. 그것은 그 자체의 장점을 지닌 세련되고 효율적이며 접근하기 쉬운 도구입니다.
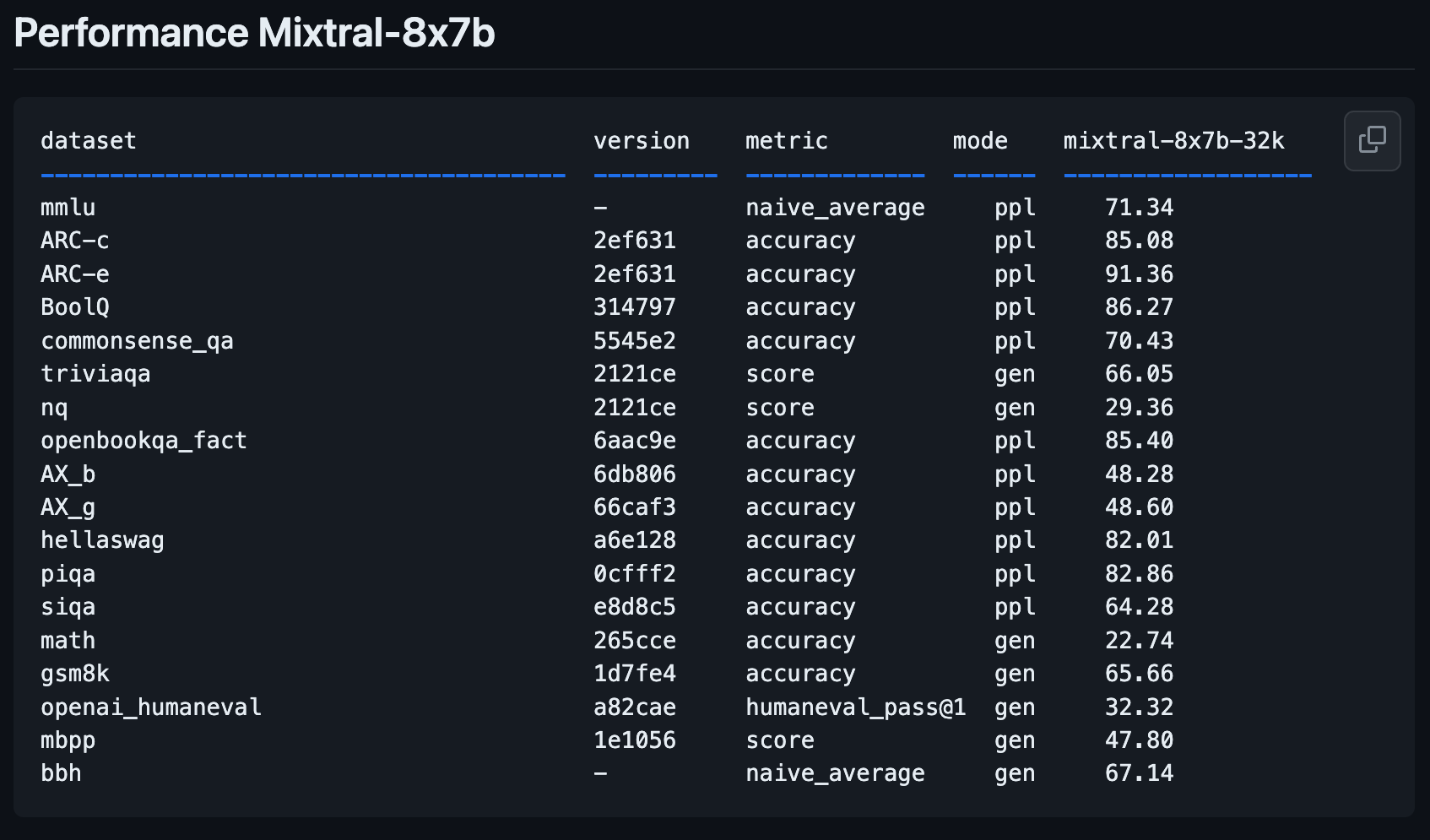
Mixtral 8x7B는 효율성과 확장성으로 최근 몇 년간 주목을 받은 개념인 전문가 혼합(MoE) 모델의 원리에 따라 작동합니다.
구체적으로 Mixtral 8x7B는 각각 70억 개의 매개변수를 가진 8명의 전문가로 구성되는데, 이는 각각 1,110억 개의 매개변수를 가진 GPT-4의 추정 8명의 전문가에 비해 상당한 규모 축소입니다. 이러한 설계 선택을 통해 Mixtral은 컴퓨팅 요구 사항 측면에서 관리하기 쉬울 뿐만 아니라 다양한 애플리케이션에 고유하게 배치됩니다.
Mixtral 8x7B의 아키텍처는 특히 매력적입니다. 처리 효율성과 속도를 최적화하는 전략인 전문가 8명 중 2명만 사용하여 토큰 추론을 위해 설계되었습니다. 이 접근 방식은 모델 메타데이터에 반영되어 해당 구성에 대한 더 깊은 통찰력을 제공합니다.
Mixtral 8x7B는 AI 환경에서 강력하면서도 접근하기 쉬운 도구입니다. 실용적인 디자인과 결합된 기술적 정교함은 강력한 LLM일 뿐만 아니라 AI 모델의 미래가 어떤 모습일지 보여주는 신호이기도 합니다. 즉, 강력하고 효율적이며 더 광범위한 사용자와 애플리케이션에 접근할 수 있습니다.
Mixtral 8x7B를 실행하는 방법 - 두 가지 현재 방법
방법 1: 이 핵으로 Mixtral 8x7B 실행
Mixtral 8x7B를 즉시 실험해보고 싶은 사람들을 위해 다소 독특하지만 기능적인 방법이 있습니다. 이 접근 방식에는 원래 Llama 코드베이스를 Mixtral 8x7B와 함께 작동하도록 조정하는 작업이 포함되지만, 이 구현은 아직 초기 단계이며 모델의 기능을 완전히 활용하지 못할 수 있다는 점에 유의하는 것이 중요합니다.
해킹의 핵심 사항:
순진하고 느림: 구현은 기본적이며 속도에 최적화되지 않았습니다.
- 하드웨어 요구 사항: 이 버전을 실행하려면 80GB GPU 2개 또는 40GB GPU 4개가 필요합니다.
- 기술적 세부정보: 이 방법에는 단순성을 위해 모델 병렬성을 제거하고 사용 가능한 GPU 전반에 걸쳐 전문가를 샤딩하는 작업이 포함됩니다. 또한 이 연구 논문을 기반으로 한 리버스 엔지니어링 MoE 구현도 포함되어 있습니다.
구현 방법:
가중치 다운로드: Mixtral 모델 가중치는 Torrent를 통해 또는 Hugging Face 저장소(Mixtral 8x7B on Hugging Face 가중치가 확보되면 2개의 GPU(각각 약 45GB 필요)에서 모델을 실행할 수 있습니다. 다음 명령을 사용합니다:
모델 실행:.
python example_text_completion.py path/to/mixtral/ path/to/mixtral/tokenizer.model
4 GPU 설정의 경우 명령에 --num-gpus 4를 추가하세요.
방법 2. Fireworks AI로 Mixtral 8x7B 실행

Mixtral 8x7B를 테스트하는 보다 사용자 친화적인 대체 방법은 Fireworks.ai를 이용하는 것입니다.
Fireworks AI는 간소화된 경험을 제공하지만 이것이 Mistral AI의 공식 구현이 아니라는 점에 유의하는 것이 중요합니다.
Fireworks.ai의 주요 기능:
- 빠른 액세스: 이 모델은 가중치가 처음 출시된 후 몇 시간 만에 사용할 수 있으며 이는 AI 커뮤니티의 민첩성과 협력 정신을 보여줍니다.
- 리버스 엔지니어링 아키텍처: Fireworks.ai의 구현은 커뮤니티와 협력하여 매개변수 이름의 아키텍처를 리버스 엔지니어링하여 달성되었습니다.
Fireworks.ai 사용: - 모델 액세스: Fireworks.ai를 방문하여 Mixtral 8x7B를 사용해 보세요.
- 주의 사항: 사용자는 이것이 공식 릴리스가 아니기 때문에 결과가 다를 수 있으며 Mistral AI가 공식 모델 코드를 릴리스하면 업데이트가 예상된다는 점에 유의해야 합니다.
방법 3. Ollama로 Mixtral 8x7B 실행
전제 조건:
- 모델 요구 사항을 수용할 수 있도록 시스템에 최소 48GB RAM이 있는지 확인하세요.
- Ollama 버전 0.1.16을 설치합니다. 이 특정 버전은 Mixtral-8x7B 모델과의 호환성을 위해 필요합니다. 제공된 링크에서 다운로드하실 수 있습니다.
모델 개요:
- Mixtral-8x7B는 Mistral AI가 개발한 최첨단 MoE(Sparse Mixture of Experts) LLM(대형 언어 모델)입니다.
- 다양한 벤치마크에서 Llama 2 70B를 능가하는 개방형 무게와 우수한 성능으로 유명합니다.
- 허용 라이센스를 사용하면 다양한 애플리케이션에 액세스할 수 있어 비용과 성능의 균형을 효율적으로 맞출 수 있습니다.
실행 명령:
- 모델을 실행하려면 ollama run mixtral:8x7b 명령을 사용하세요. 이 명령은 OLLAMA 환경 내에서 모델을 시작합니다.
사용 팁:
- OLLAMA에 맞게 환경이 올바르게 구성되어 있는지 확인하세요. 설정해야 하는 종속성 또는 환경 변수가 있는지 확인하세요.
- 명령을 실행한 후 모델이 시작되어야 합니다. 시스템 사양에 따라 초기화 시간이 다를 수 있습니다.
실행 후:
- 모델이 실행되면 프로젝트 요구 사항에 따라 모델과 상호 작용할 수 있습니다.
- 이 모델은 다양한 생성 작업에 적합하므로 연구 및 실제 응용 분야 모두에 다용도로 사용할 수 있습니다.
지원 및 업데이트:
- 최근 업데이트 및 사용 통계(871개 이상)에서 알 수 있듯이 정기적인 업데이트 및 지원이 가능합니다.
- 문제 해결 및 자세한 지침은 Mistral AI 문서 또는 커뮤니티 포럼을 참조하세요.
링크: https://ollama.ai/library/mixtral
Mistral AI: 마을 최고의 AI 회사
Mixtral 8x7B의 출시는 AI 커뮤니티 전체에 파문을 일으키며 그 중요성을 강조하는 다양한 반응을 불러일으켰습니다.
매니아, 전문가 및 개발자가 모두 참여하여 모델의 영향을 여러 각도에서 강조했습니다.
긍정적인 소문과 건설적인 비판: 많은 사람들이 Mistral AI의 혁신적인 접근 방식과 모델의 기술적 역량을 칭찬하는 등 반응은 대체로 긍정적이었습니다.
AI 컨설턴트인 Uri Eliabayev는 Mistral의 대담한 출시 전략을 칭찬했습니다.
유명한 기업가인 George Hotz는 AI 분야에서 가장 선호하는 브랜드인 Mistral의 브랜드에 대해 감사를 표시했습니다.
이러한 열정은 GPT-4와 같은 대형 모델에 비해 모델의 한계에 주로 초점을 맞춘 건설적인 비판에 의해 완화되지만 이러한 비판조차도 Mixtral 8x7B의 잠재력을 인정합니다.
아마도 가장 중요한 것은 AI 커뮤니티가 오픈 소스 원칙에 대한 Mistral AI의 헌신에 대해 강한 감사를 표했다는 것입니다. 이러한 접근 방식은 AI 기술을 민주화하여 더 폭넓은 사용자와 개발자가 더 쉽게 접근할 수 있도록 하는 단계로 환영받았습니다.
Mistral AI: Mixtral 8x7B를 사용하여 오픈 소스 LLM에 대한 새로운 표준 설정
미래를 내다보면 Mixtral 8x7B가 AI 환경에 미치는 영향이 점점 더 분명해집니다.
Mixtral 8x7B 출시 및 설계에 대한 Mistral AI의 접근 방식은 AI 모델 개발 및 보급을 위한 새로운 표준을 설정할 수 있습니다.
Mixtral 8x7B는 더 많은 오픈 소스 AI 솔루션을 향한 중요한 추진을 나타냅니다.
그 성공은 더 많은 기업이 유사한 접근 방식을 채택하도록 영감을 주어 잠재적으로 보다 다양하고 혁신적인 AI 연구 환경으로 이어질 수 있습니다.
Mistral AI의 Mixtral 8x7B가 AI 및 LLM 개발의 미래를 어떻게 변화시킬 것인가?
Mixtral 8x7B에 대한 열광적인 반응과 이로 인해 촉발된 대화는 보다 개방적이고 협력적인 AI 개발을 향한 추세가 커지고 있음을 나타냅니다. 이 모델은 다양한 애플리케이션에 귀중한 도구를 제공했을 뿐만 아니라 AI 분야의 혁신, 탐구 및 토론을 위한 새로운 길을 열었습니다.
우리가 기대하는 대로 Mixtral 8x7B는 AI의 미래를 형성하는 데 중요한 역할을 할 준비가 되어 있습니다. 그 영향은 산업과 커뮤니티 전반에 걸쳐 느껴져 더욱 발전하고 최첨단 AI 기술에 대한 접근이 민주화될 것입니다. 요약하자면, Mixtral 8x7B는 Mistral AI의 단순한 이정표가 아닙니다. 이는 AI 커뮤니티 전체의 이정표이며, 보다 포괄적이고 협력적이며 개방적인 AI 개발을 향한 전환을 의미합니다.