
티스토리 뷰
Google의 내부 소프트웨어 시스템은 지난 25년 동안 말 그대로 엔지니어가 수행하는 모든 작업에 대한 원격 측정을 캡처해 왔습니다 . 이를 함께 연결하면 소프트웨어 엔지니어링 보조원을 위한 멋진 교육 데이터 세트가 됩니다.
DIDACT (Dynamic Integrated Developer ACTivity)는 최종 제품뿐만 아니라 전체 소프트웨어 개발 프로세스에서 기계 학습 모델을 훈련하기 위한 방법론입니다. 이 접근 방식을 통해 모델은 개발자의 워크플로를 더 잘 이해하고 조정할 수 있습니다.
Google의 방대한 소프트웨어 개발 로그는 DIDACT를 촉진하여 풍부한 교육 데이터 세트를 제공합니다. 주요 기능은 다음과 같습니다:
- 편집 및 디버깅과 같은 활동을 다루는 다중 작업 모델입니다.
- 세 가지 도구 개발: 댓글 해결, 빌드 복구, 팁 예측. Google 개발자로부터 긍정적인 피드백을 받았습니다.
- 복잡한 동작을 표현하기 위해 미니 프로그래밍 언어인 "DevScript"를 사용합니다.
- 기능에는 코드 정리, 기록으로 보강된 코드 완성, 편집 예측이 포함됩니다.
본질적으로 DIDACT는 Google의 소프트웨어 개발 활동을 ML 개발자 보조자를 위한 교육 데모로 전환하여 소프트웨어 엔지니어의 생산성과 작업 품질을 향상시킵니다.
소프트웨어는 하나의 극적인 단계로 만들어지지 않습니다. 편집, 단위 테스트 실행, 빌드 오류 수정, 코드 검토 해결, 추가 편집, 린터 완화 , 더 많은 오류 수정 등 한 번에 한 단계씩 조금씩 개선되어 마침내 코드로 병합할 수 있을 정도로 좋아집니다. 저장소. 소프트웨어 엔지니어링은 고립된 프로세스가 아니라 인간 개발자, 코드 검토자, 버그 보고자, 소프트웨어 설계자 및 도구(예: 컴파일러, 단위 테스트, 린터 및 정적 분석기) 간의 대화입니다.
오늘은 소프트웨어 개발을 위한 대규모 머신러닝(ML) 모델을 훈련하는 방법론인 DIDACT(Dynamic Integrated Developer ACTivity)에 대해 설명합니다. DIDACT의 참신함은 해당 프로세스의 최종 상태인 완성된 코드가 아니라 소프트웨어 개발 프로세스를 모델에 대한 교육 데이터 소스로 사용한다는 것입니다 . 개발자가 작업하면서 보는 컨텍스트에 모델을 노출하고 이에 대한 응답으로 취하는 조치를 취함으로써 모델은 소프트웨어 개발의 역학에 대해 학습하고 개발자가 시간을 보내는 방식에 더욱 부합합니다. 우리는 Google의 소프트웨어 개발 도구를 활용하여 이전 작업보다 개발자 활동 데이터의 양과 다양성을 확장합니다. 결과는 두 가지 측면에서 매우 유망합니다. 전문 소프트웨어 개발자에게 유용하다는 것과 ML 모델에 일반적인 소프트웨어 개발 기술을 주입하기 위한 잠재적 기반이라는 것입니다.
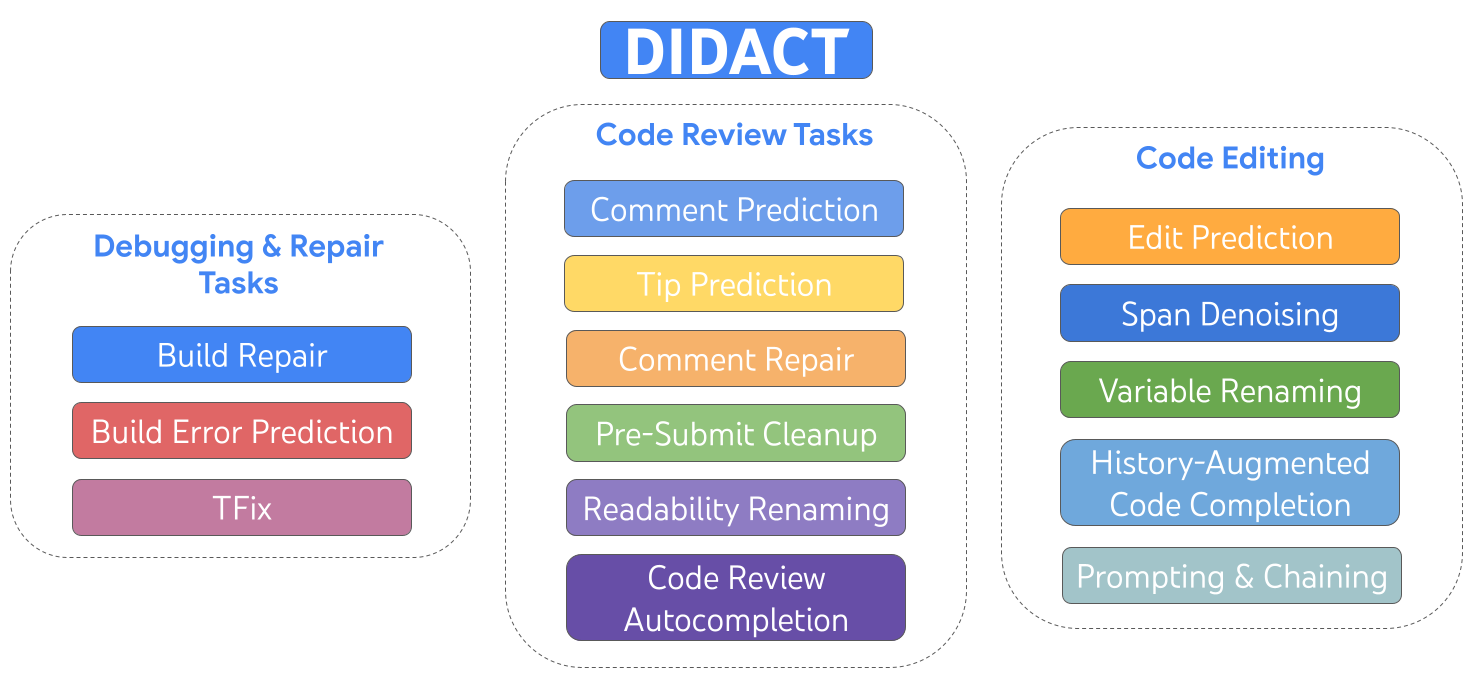 |
| DIDACT는 편집, 디버깅, 복구, 코드 검토를 포함한 개발 활동에 대해 훈련된 다중 작업 모델입니다. |
우리는 세 가지 DIDACT 도구 , 즉 최근 발표한 Comment Resolution , Build Repair, Tip Prediction을 구축하고 배포했습니다 . 각각은 개발 워크플로의 서로 다른 단계에 통합되어 있습니다. 이 세 가지 도구 모두 수천 명의 내부 개발자로부터 열정적인 피드백을 받았습니다. 우리는 이것을 유용성에 대한 궁극적인 테스트라고 봅니다. 코드 기반에 대한 전문가이고 신중하게 워크플로를 연마한 전문 개발자가 도구를 활용하여 생산성을 향상합니까?
아마도 가장 흥미로운 점은 DIDACT가 어떻게 범용 개발자 지원 에이전트를 향한 첫 번째 단계인지 보여주는 것입니다. 우리는 훈련된 모델이 개발자 활동의 접두사를 사용하여 프롬프트를 표시하고 여러 예측을 연결하여 더 긴 활동 궤적을 롤아웃하는 등 다양하고 놀라운 방식으로 사용될 수 있음을 보여줍니다. 우리는 DIDACT가 소프트웨어 개발 프로세스 전반에 걸쳐 일반적으로 도움을 줄 수 있는 에이전트 개발을 향한 유망한 길을 열어준다고 믿습니다.
소프트웨어 엔지니어링 프로세스에 관한 데이터의 보고
Google의 소프트웨어 엔지니어링 도구 모음은 코드와 관련된 모든 작업을 도구와 개발자 간의 상호 작용 로그로 저장하며 수십 년 동안 그렇게 해왔습니다. 원칙적으로 이 기록을 사용하여 Google의 코드베이스가 어떻게 되었는지에 대한 "소프트웨어 엔지니어링 비디오"의 주요 에피소드를 단계별로(코드 편집, 편집, 주석, 변수 이름 변경 등) 자세히 재생할 수 있습니다. 한 번에.
Google 코드는 모든 도구와 시스템을 위한 단일 코드 저장소인 모노레포(monorepo )에 있습니다 . 소프트웨어 개발자는 일반적으로 CitC( 클라이언트 인 더 클라우드 ) 라는 시스템이 관리하는 로컬 쓰기 시 복사 작업 공간에서 코드 변경을 실험합니다. 개발자가 특정 목적(예: 버그 수정)을 위해 일련의 코드 변경 사항을 함께 패키징할 준비가 되면 Google의 코드 검토 시스템인 Critique 에서 변경 목록(CL)을 만듭니다 . 다른 유형의 코드 검토 시스템과 마찬가지로 개발자는 동료 검토자와 기능 및 스타일에 대한 대화에 참여합니다. 개발자는 대화가 진행됨에 따라 검토자의 의견을 처리하기 위해 CL을 편집합니다. 결국 리뷰어는 “LGTM!”을 선언합니다. ("나에게 좋아 보인다") CL은 코드 저장소에 병합됩니다.
물론 코드 검토자와의 대화 외에도 개발자는 컴파일러, 테스트 프레임워크, 린터, 정적 분석기, 퍼저 등과 같은 수많은 다른 소프트웨어 엔지니어링 도구와의 일종의 "대화"를 유지 관리합니다.
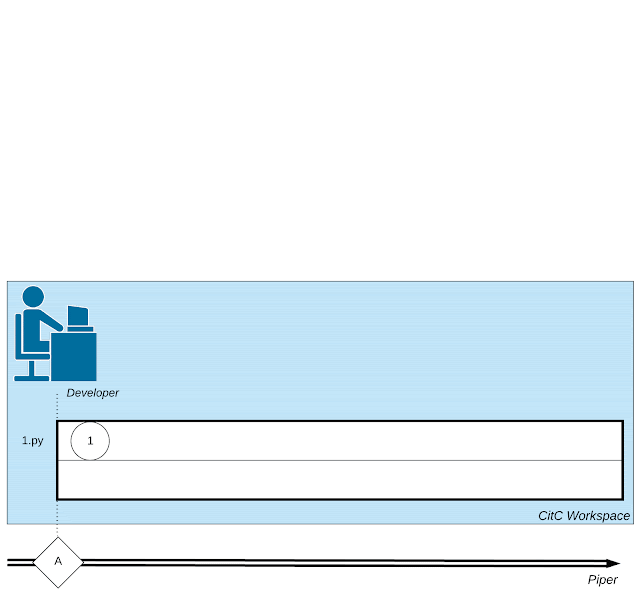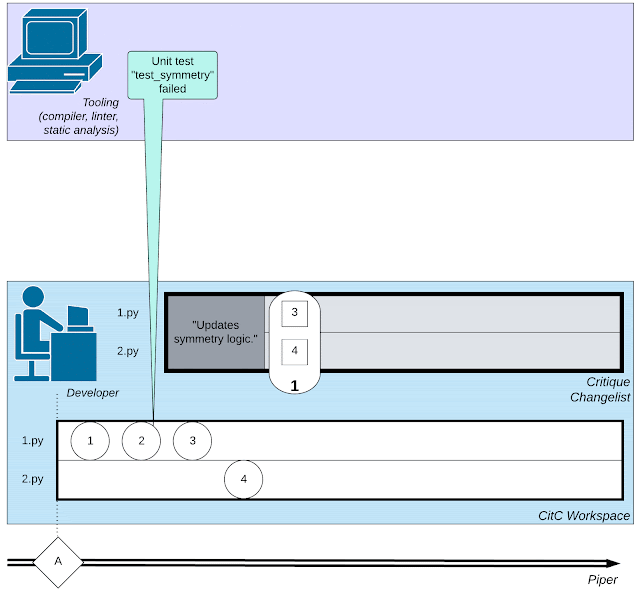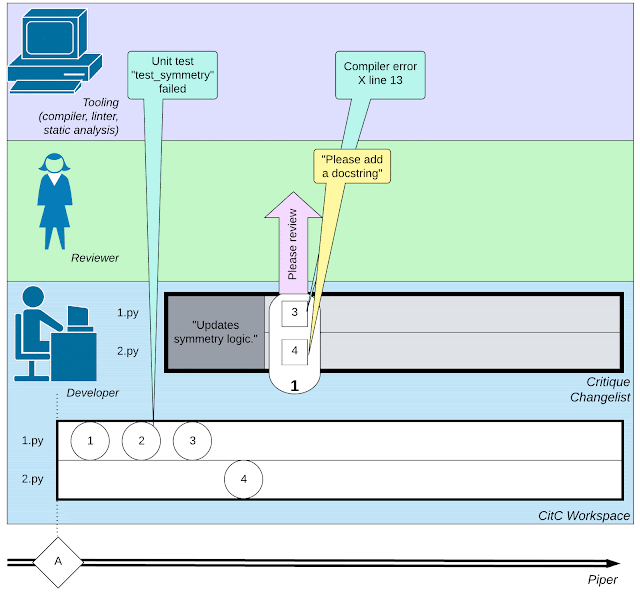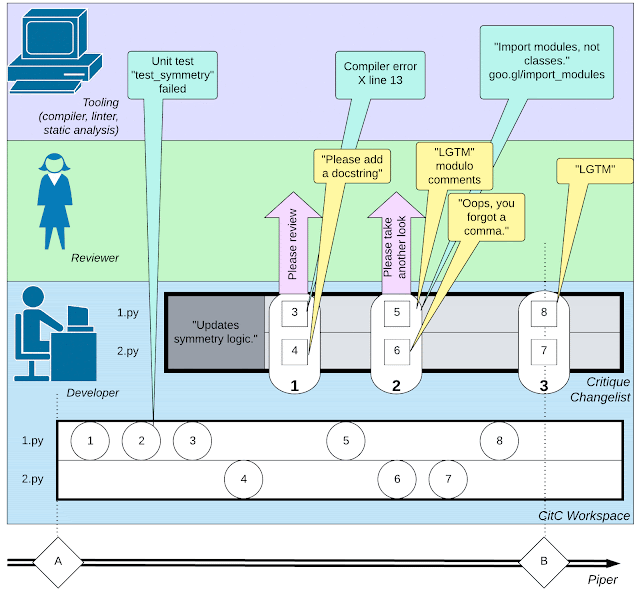 |
| 소프트웨어 개발과 관련된 복잡한 웹 활동(개발자의 작은 작업, 코드 검토자와의 상호 작용, 컴파일러와 같은 도구 호출)을 보여줍니다. |
소프트웨어 엔지니어링을 위한 다중 작업 모델
DIDACT는 엔지니어와 도구 간의 상호 작용을 활용하여 소프트웨어 엔지니어링 작업을 수행하는 동안 상황에 맞게 개발자가 취하는 작업을 제안하거나 향상함으로써 Google 개발자를 지원하는 ML 모델을 강화합니다. 이를 위해 우리는 손상된 빌드 복구, 코드 검토 주석 예측, 코드 검토 주석 처리, 변수 이름 변경, 파일 편집 등 개별 개발자 활동에 대한 여러 작업을 정의했습니다. 우리는 공통 형식을 사용합니다. 각 활동에 대해 상태 (코드 파일), 인 텐트 (코드 검토 주석 또는 컴파일러 오류와 같은 활동에 특정한 주석)를 취하고 작업 (작업을 해결하기 위해 수행되는 작업 )을 생성합니다. 이 Action은 미니 프로그래밍 언어와 같으며 새로 추가된 활동을 위해 확장될 수 있습니다. 여기에는 편집, 주석 추가, 변수 이름 바꾸기, 오류가 있는 코드 표시 등과 같은 작업이 포함됩니다. 우리는 이 언어를 DevScript 라고 부릅니다.
 |
| DIDACT 모델은 해당 작업과 관련된 작업, 코드 조각 및 주석을 표시하고 편집 또는 댓글과 같은 개발 작업을 생성합니다. |
이러한 상태-의도-행동 형식주의를 통해 우리는 일반적인 방식으로 다양한 작업을 포착할 수 있습니다. 게다가 DevScript는 작업이 발생한 후의 전체 상태(원본 코드)를 출력할 필요 없이 복잡한 작업을 표현하는 간결한 방법입니다. 이는 모델을 더욱 효율적이고 해석하기 쉽게 만듭니다. 예를 들어 이름 바꾸기는 파일의 여러 위치에 영향을 미칠 수 있지만 모델은 단일 이름 바꾸기 작업을 예측할 수 있습니다.
ML 동료 프로그래머
DIDACT는 개별 보조 작업을 훌륭하게 수행합니다. 예를 들어 아래에서는 기능이 대부분 완료된 후 DIDACT가 코드 정리를 수행하는 모습을 보여줍니다. 코드 검토자의 최종 의견(애니메이션에서 "사람"으로 표시됨)과 함께 코드를 살펴보고 해당 의견을 해결하기 위한 편집 내용을 예측합니다( diff 로 렌더링됨 ).
 |
| 코드의 초기 조각과 코드 검토자가 해당 조각에 첨부한 주석이 주어지면 DIDACT의 사전 제출 정리 작업은 해당 주석을 처리하는 편집(텍스트 삽입 및 삭제)을 생성합니다. |
DIDACT의 다중 모드 특성은 또한 규모에 따라 나타나는 행동을 연상시키는 몇 가지 놀라운 기능을 제공합니다 .
이러한 기능 중 하나는 프롬프트를 통해 활성화할 수 있는 기록 확대 입니다. 개발자가 최근에 무엇을 했는지 알면 모델은 개발자가 다음에 무엇을 해야 하는지 더 잘 추측할 수 있습니다.
Characterizing Emergent Phenomena in Large Language Models
Posted by Jason Wei and Yi Tay, Research Scientists, Google Research, Brain Team The field of natural language processing (NLP) has been revolutionized by language models trained on large amounts of text data. Scaling up the size of language models often l
blog.research.google
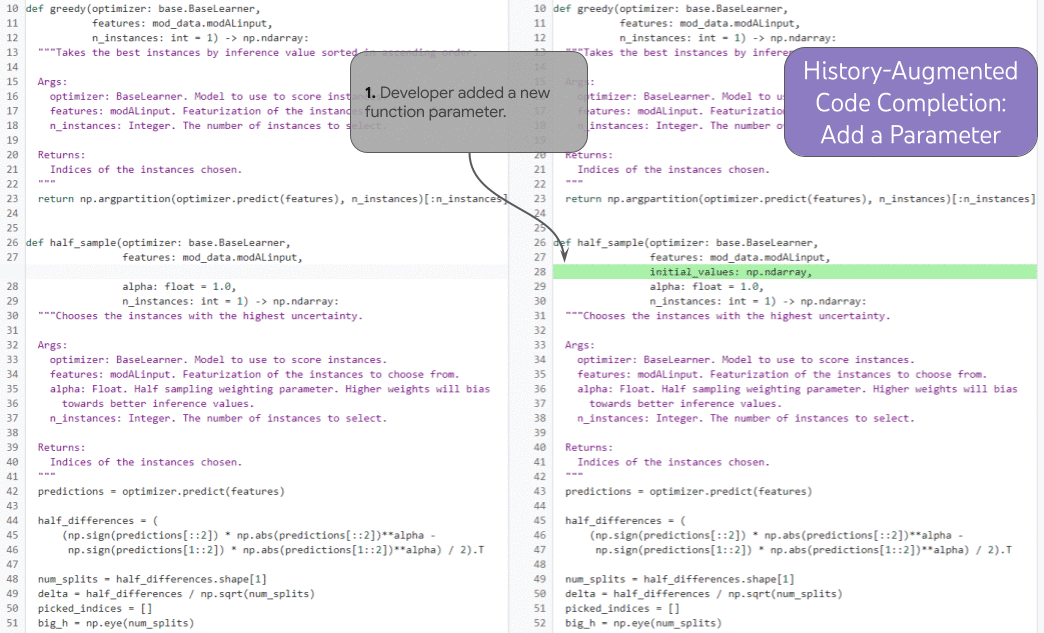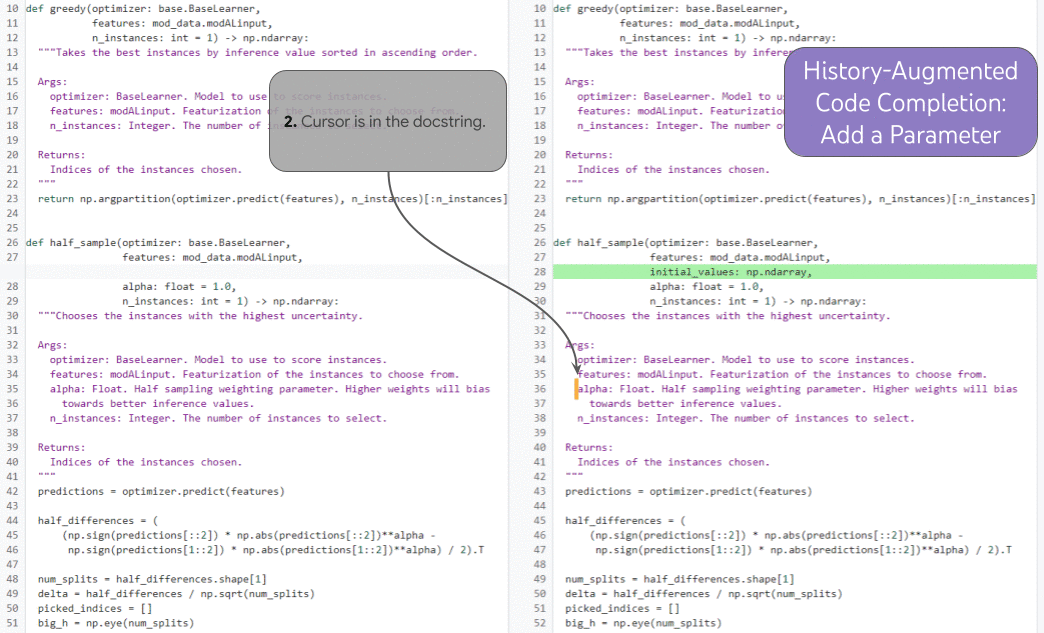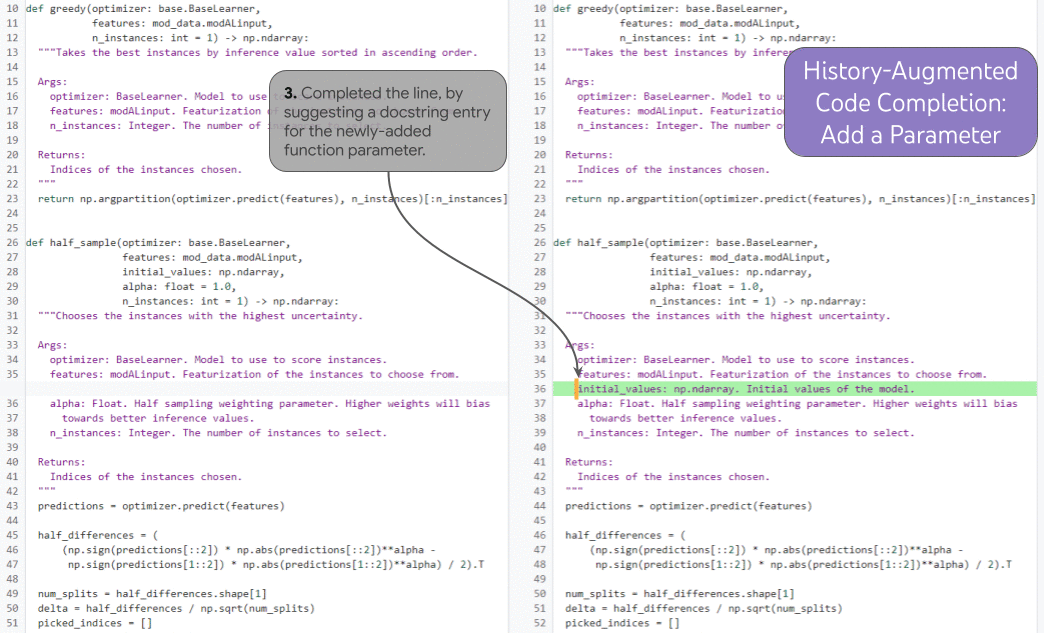 |
| 기록을 기반으로 한 코드 완성이 실제로 수행되는 모습을 보여줍니다. |
이 기능을 예시하는 강력한 작업은 기록 증강 코드 완성 입니다 . 아래 그림에서 개발자는 새 함수 매개변수를 추가하고(1) 문서로 커서를 이동합니다(2). 개발자 편집 내역과 커서 위치를 조건으로 모델은 새 매개변수에 대한 독스트링 항목을 올바르게 예측하여 라인 (3)을 완성합니다.
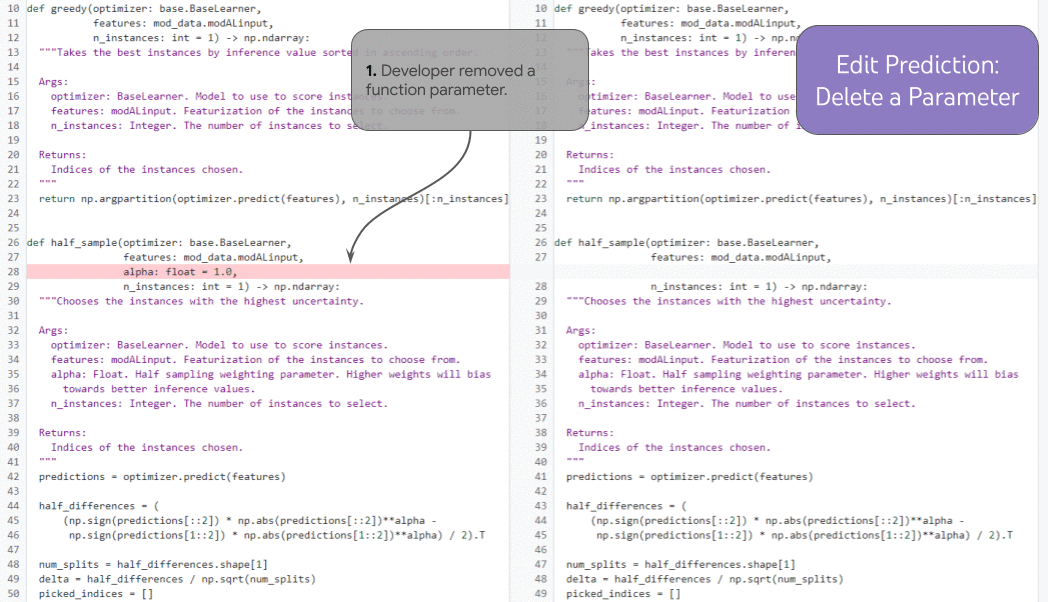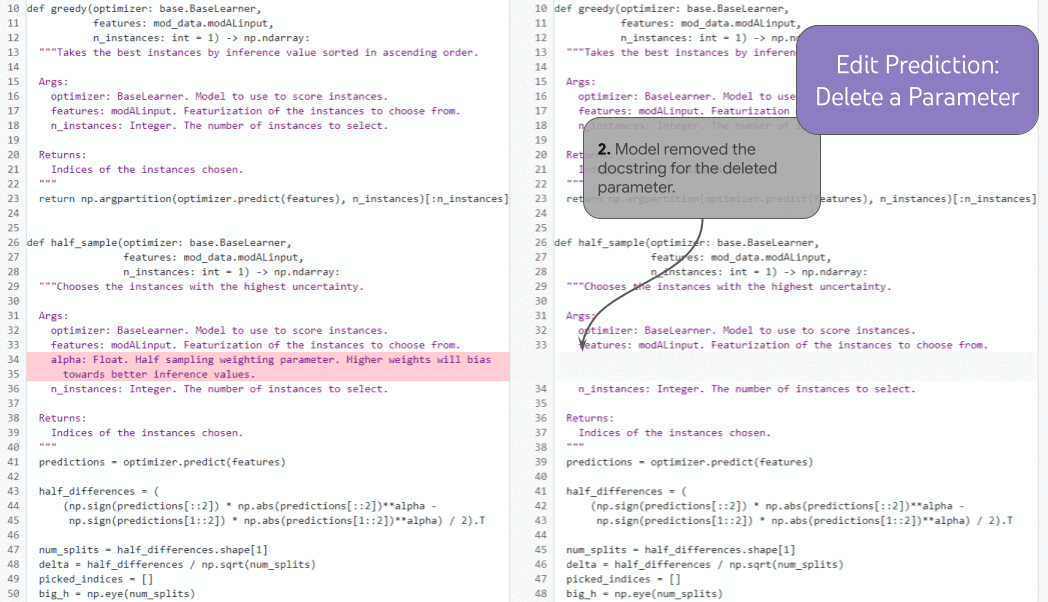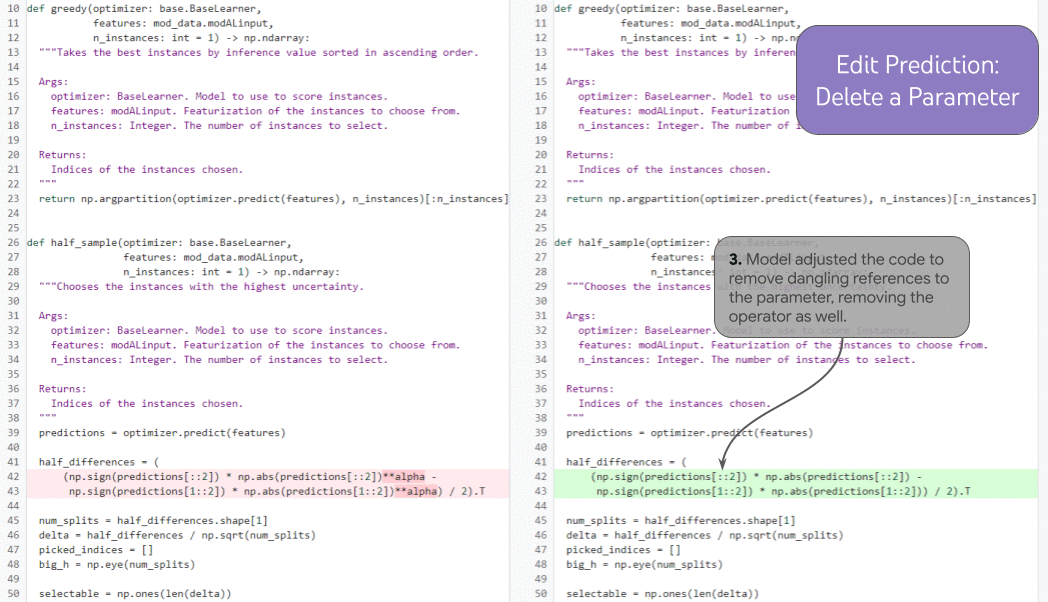 |
| 여러 개의 연결된 반복에 대한 편집 예측을 보여줍니다. |
훨씬 더 강력한 기록 증강 작업인 예측 편집 에서 모델은 역사적으로 일관된 방식으로 다음에 편집할 위치를 선택할 수 있습니다 . 개발자가 함수 매개변수(1)를 삭제하면 모델은 기록을 사용하여 삭제된 매개변수를 제거하는 독스트링(2)에 대한 업데이트를 올바르게 예측하고(개발자가 수동으로 커서를 거기에 배치하지 않고도) 명령문을 업데이트할 수 있습니다. (3)을 구문론적으로 (그리고 — 틀림없이 — 의미론적으로) 올바른 방식으로 작동합니다. 기록을 통해 모델은 "비디오 편집"을 올바르게 계속하는 방법을 명확하게 결정할 수 있습니다. 기록이 없으면 모델은 누락된 함수 매개변수가 의도적인 것인지(개발자가 이를 제거하기 위해 장기간 편집하는 중이기 때문에) 또는 우발적인 것인지(이 경우 문제를 해결하기 위해 모델이 이를 다시 추가해야 함) 여부를 알 수 없습니다. .
모델은 더욱 발전할 수 있습니다. 예를 들어 빈 파일로 시작하여 전체 코드 파일이 작성될 때까지 다음에 어떤 편집이 이루어질지 연속적으로 예측하도록 모델에 요청했습니다. 놀라운 부분은 모델 이 개발자에게 자연스럽게 보일 수 있는 단계별 방식으로 코드를 개발했다는 것입니다 . 먼저 가져오기, 플래그 및 기본 기본 기능을 포함하여 완벽하게 작동하는 뼈대를 만드는 것부터 시작했습니다. 그런 다음 파일 읽기 및 결과 쓰기와 같은 새로운 기능을 점진적으로 추가하고 사용자가 제공한 정규식을 기반으로 일부 줄을 필터링하는 기능을 추가했습니다. 이를 위해서는 새 플래그 추가와 같이 파일 전반에 걸쳐 변경이 필요했습니다.
결론
DIDACT는 Google의 소프트웨어 개발 프로세스를 ML 개발자 보조자를 위한 교육 데모로 전환하고 이러한 데모를 사용하여 도구 및 코드 검토자와 대화형으로 단계별 방식으로 코드를 구성하는 모델을 교육합니다. 이러한 혁신은 이미 Google 개발자들이 매일 즐기고 있는 도구를 강화하고 있습니다. DIDACT 접근 방식은 소프트웨어 엔지니어의 수고를 덜어주고, 생산성을 향상시키며, 작업 품질을 향상시키는 기술을 향한 Google 및 다른 곳의 대규모 언어 모델이 취한 큰 진전을 보완합니다.
감사의 말
이 작업은 Google Research, Google Core Systems and Experiences, DeepMind 간의 다년간의 협력의 결과입니다. 이 프로젝트의 핵심 동인으로 합류한 동료 Jacob Austin, Pascal Lamblin, Pierre-Antoine Manzagol 및 Daniel Zheng에게 감사를 표하고 싶습니다. 이 작업은 Alphabet의 파트너(Peter Choy, Henryk Michalewski, Subhodeep Moitra, Malgorzata Salawa, Vaibhav Tulsyan 및 Manushree Vijayvergiya)뿐만 아니라 데이터를 수집하고 작업을 식별한 많은 사람들의 중요하고 지속적인 기여 없이는 이루어질 수 없었을 것입니다. , 제품을 구축하고, 전략을 세우고, 전파하고, 이 안건의 다양한 측면을 실행하는 데 도움을 주었습니다(Ankur Agarwal, Paige Bailey, Marc Brockschmidt, Rodrigo Damazio Bovendorp, Satish Chandra, Savinee Dancs, Denis Davydenko, Matt Frazier, Alexander Frömmgen, Nimesh Ghelani , Chris Gorgolewski, Chenjie Gu, Vincent Hellendoorn, Franjo Ivančić, Marko Ivanković, Emily Johnston, Luka Kalinovcic, Lera Kharatyan, Jessica Ko, Markus Kusano, Kathy Nix, Christian Perez, Sara Qu, Marc Rasi, Marcus Revaj, Ballie Sandhu, Michael Sloan, Tom Small, Gabriela Surita, Maxim Tabachnyk, Stephanie Tang, David Tattersall, Sara Toth, Kevin Villela, Sara Wiltberger 및 Donald Duo Zhao)와 우리의 매우 지원적인 리더십(Martín Abadi, Joelle Barral, Jeff Dean, Madhura Dudhgaonkar, Douglas) Eck, Zoubin Ghahramani, Hugo Larochelle, Chandu Thekkath 및 Niranjan Tulpule). 감사합니다!
'AI 생태계' 카테고리의 다른 글
| 자연어처리 AI 모델 PaLM 2 소개 (0) | 2023.10.27 |
|---|---|
| D-ID - AI를 사용하여 사진으로 비디오 만들기 (0) | 2023.10.26 |
| 비기술 브랜드가 AI를 활용하는 방법: 패션 (0) | 2023.10.24 |
| 웹용 포토샵 어도비 파이어플라이 (0) | 2023.10.22 |
| 어도비의 2024 AI로 펼쳐지는 차세대 크리에이티브 세상 (0) | 2023.10.22 |